This guide walks through running DeepSeek-V4-class open weights on a Mac with Apple Silicon using Apple’s MLX stack and the community mlx-lm Python package. It follows the same structure as the editorial runbook under editorial/deepseek-v4-mlx-lm/, but ties install choices to what is landing in PR #1192 (Add DeepSeek-v4 (Flash/Pro)) on the upstream repo — MoE loading, dtype fallbacks, and routing fixes — while staying honest about merge status, unified-memory limits, and when the hosted API is the sane option.
mlx-lm revision that actually contains a DeepSeek V4 model implementation. If upstream main has not merged the V4 path yet, you install from a PR branch or fork until PyPI catches up — then you run mlx_lm.generate, mlx_lm.chat, optional prompt caching, and optionally an OpenAI-style local server if your build exposes it.API vs local weights
Hosted API sends prompts to DeepSeek’s infrastructure; you pay per token and inherit their capacity planning. For model names, thinking modes, pricing, and retirement dates, use the on-site explainer DeepSeek V4 Preview: API models and 1M context as the cloud-facing companion to this page.
Local MLX keeps tokens on your machine: you download open weights (typically from Hugging Face), match them to an mlx-lm build that understands the V4 architecture, and accept that unified RAM is the ceiling. For a different local stack (Gemma on-device), see how to install and run Gemma 4 locally.
Hardware and macOS
Apple Silicon is the realistic target for mlx / mlx-lm; do not expect Intel Macs to be a serious path for large MoE inference. The mlx-lm README also notes that some large-model memory wiring behaviours expect macOS 15.0 or newer; below that you may still run models, but paging and pressure spikes get more likely.
V4-class models are mixture-of-experts designs with very different total vs active parameter stories between Flash and Pro. For local experimentation, assume Flash-oriented builds and aggressive quantisation first; Pro-class loads are mainly realistic on very large unified memory configurations.
| Unified RAM (rule of thumb) | What is usually realistic |
|---|---|
| 16–24 GB | Unpleasant for V4-class MoE at meaningful context; prefer smaller MLX models locally and use the API for V4-sized work. |
| 36–48 GB | Heavily quantised Flash-class setups may load if weights and mlx-lm revision align; expect friction and short context. |
| 64–96 GB | More workable for Flash with strong quantisation and disciplined max_kv_size / caching. |
| 128 GB | Common serious local MoE tier; still requires conservative settings. |
| 256 GB | Aligns with the class of machine discussed in PR #1192 commentary around keeping experts quantised (for example 4-bit) while fitting the footprint — a memory signal, not a speed guarantee. |
The upstream README documents an advanced sysctl knob (iogpu.wired_limit_mb) for some large-model cases. If you do not understand the tradeoff, skip it and reduce model size, context, or quantisation requirements instead.
Install: PyPI stable vs PR branch
Path A — PyPI (best once main contains V4 support and a release you trust):
python3 -m venv .venv
source .venv/bin/activate
python -m pip install -U pip
pip install -U mlx mlx-lmSmoke test:
python -c "import mlx_lm; print('mlx-lm import OK')"Path B — PR #1192 branch (when upstream is still catching up): the open pull request Add DeepSeek-v4 (Flash/Pro) tracks MoE expert quantisation, safetensors dtype fallbacks, batched routing, and related fixes. Install from the contributor branch only after you confirm the branch name in the PR header (names can change):
python3 -m venv .venv
source .venv/bin/activate
python -m pip install -U pip
pip install -U mlx
pip install "git+https://github.com/Blaizzy/mlx-lm.git@pc/add-deepseekv4flash-model"If pip cannot resolve the ref, open the PR on GitHub and copy the current head branch from the merge box. PR installs are fine for experiments; plan deliberate upgrades to pick up security fixes from main.
Prepare the environment
- Xcode Command Line Tools (once):
xcode-select --install - Dedicated virtualenv — never install into the system Python.
- After installing
mlx-lm(Path A or B), verify the CLI:python -m mlx_lm.generate -h | head - Optional Hugging Face login if repos are gated or rate-limited:
pip install -U "huggingface_hub[cli]"thenhuggingface-cli login
Pick a Hugging Face repo you can load
mlx-lm loads by Hugging Face repo id (for example mlx-community/SomeModel-4bit). Search for DeepSeek + V4 + mlx and filter mlx-community when possible.
A repo is runnable only when:
- your installed
mlx-lmincludes the model implementation (for example adeepseek_v4module after the V4 merge path exists), and - the checkpoint’s layout and dtypes match what that revision can load or dequantize.
Discussion on PR #1192 calls out generalised safetensors dtype fallback and FP4-style dequant paths in mlx_lm/models/deepseek_v4.py — meaning you should not assume every upload “just works” until you have matched revision and weight format.
First run: mlx_lm.generate
Replace YOUR_REPO_ID with a real MLX-compatible identifier:
source .venv/bin/activate
mlx_lm.generate \
--model YOUR_REPO_ID \
--prompt "Explain MLX unified memory in 6 bullets." \
--max-tokens 256Flags you will use often (see mlx_lm.generate -h on your machine):
--model— Hugging Face repo id.--max-tokens— completion cap.--max-kv-size n— rotating KV bound; saves RAM, can hurt quality if set too small.--trust-remote-code— sometimes required for tokenizers; only on repos you trust.
Example with a bounded KV cache:
mlx_lm.generate \
--model YOUR_REPO_ID \
--prompt "Summarize the mlx-lm DeepSeek V4 PR in 10 lines." \
--max-tokens 256 \
--max-kv-size 4096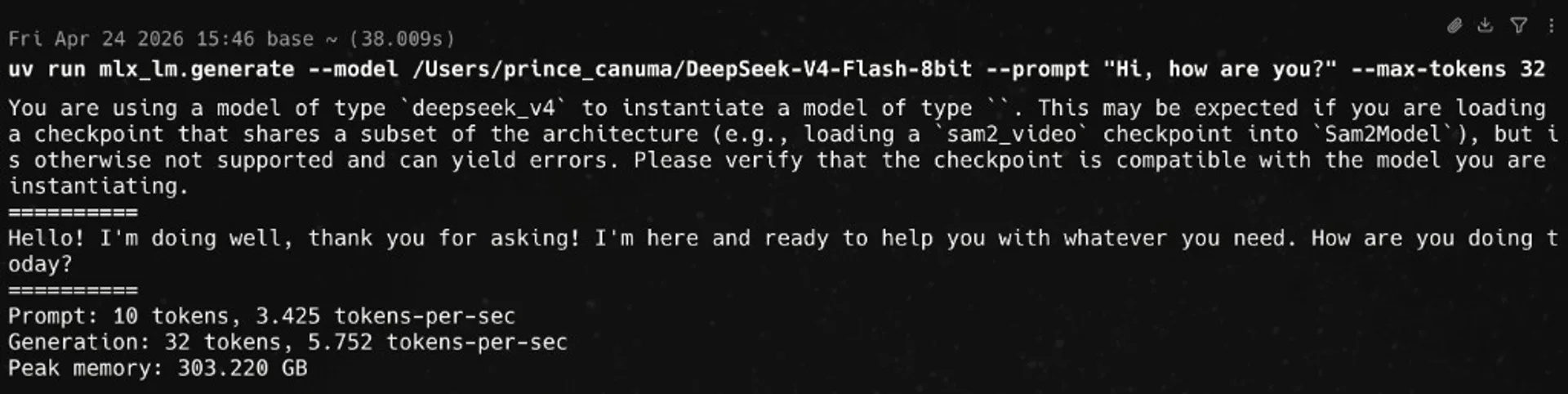
uv run mlx_lm.generate against a local checkpoint path (here Flash-class 8-bit), showing throughput and peak unified memory — your numbers will vary by chip, OS, and weight revision.Interactive mlx_lm.chat
The upstream README documents a REPL that preserves context for the session lifetime:
mlx_lm.chat --model YOUR_REPO_IDUse -h on your installed version for sampling and system-prompt options.
Long prompts: KV bounds and prompt caching
MoE models are sensitive to KV memory. The README’s Long Prompts and Generations section describes a rotating fixed-size KV cache (--max-kv-size) and prompt caching: build a cache file for a large static prefix, then reuse it as a prefix for follow-up queries via mlx_lm.cache_prompt and --prompt-cache-file on generation. For RAG-style workloads, caching is often higher leverage than micro-optimising batch size.
Python API and streaming
Minimal streaming pattern (same spirit as the README “Python API” / “Streaming” examples):
from mlx_lm import load, stream_generate
repo = "YOUR_REPO_ID"
model, tokenizer = load(repo)
messages = [{"role": "user", "content": "Write a haiku about Apple Silicon."}]
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
for response in stream_generate(model, tokenizer, prompt, max_tokens=256):
print(response.text, end="", flush=True)
print()OpenAI-compatible server (optional)
Many revisions ship an HTTP server that speaks an OpenAI-like /v1 surface; the exact entry point moves between releases. Try:
python -m mlx_lm.server -h
# if that fails:
mlx_lm.server -hIf the module exists, a typical pattern is python -m mlx_lm.server --model YOUR_REPO_ID, then point your client at the printed host and port.
What PR #1192 changes operationally
This is not a substitute for reading the diff, but it tells you what to watch for when something “almost loads”:
- MoE experts — keeping experts quantised (for example 4-bit) is part of fitting large MoE footprints on unified memory; PR discussion ties that to high-RAM Mac classes.
- Performance — fixes around FP32 promotion and batched routing separate “runs” from “runs at usable tokens per second.”
- Correctness — prefill fixes in
generate_stepmatter if you feed prompts viainput_embeddingsor similar paths.
Maintainers and contributors may consolidate overlapping work (other PRs in the same area have been discussed in thread); always read the latest PR state before pinning a production dependency on a fork.
Troubleshooting
- Slow generation — check Memory pressure in Activity Monitor; confirm macOS meets README large-model notes; reduce quantisation footprint or context.
- Tokenizer / remote code — try
--trust-remote-codeonly for trusted repos. - dtype / safetensors errors — record exact HF repo id,
mlx-lmcommit, and traceback when opening an issue or PR comment; dtype fallbacks are an active integration surface in the V4 work.
Safety and licensing
Respect the license on the weights you download. --trust-remote-code is a real security surface — treat it like executing arbitrary code. Local inference avoids sending prompts to a cloud vendor, but logs, crash reporters, and adjacent tools can still leak data if you are careless.
Sources
- ml-explore/mlx-lm — README, CLI, Python API, long-context notes.

Local AI Masterclass: LLMs, Diffusion & AI-Agents on Your PC
Available at Udemy — broader local-AI path (LLMs, diffusion, agents) alongside this Mac MLX runbook. Course title, curriculum, and price change; confirm on the merchant page before you buy.
Frequently asked questions
Should I use PyPI or the PR branch?
Use PyPI when main already contains the V4 model path and a release you trust. Use the PR branch only while you explicitly need unreleased fixes; re-check GitHub merge status before documenting the path for a team.
Will DeepSeek-V4-Pro run on my laptop?
Maybe in theory with extreme quantisation and tiny context; in practice most readers should plan around Flash-class builds and treat Pro as a workstation-only experiment unless you have very large unified memory and patience to tune.
Does this replace the DeepSeek API?
No. Local MLX is for privacy, offline, or research constraints. For hosted model IDs, thinking modes, and pricing, use DeepSeek’s official API documentation and the companion article linked in section 1.
Where is the editorial Markdown original?
The repo maintains a longer-form Markdown runbook at editorial/deepseek-v4-mlx-lm/guide-run-deepseek-v4-mlx-lm.md for drafts and diffs; this HTML page is the reader-facing guide shape for the site.
Re-verify PR merge state, HF repo id, and mlx-lm version the day you run commands- all three drift faster than prose.


pretty useless without an actual model that fits in an actual macbook