On 24 April 2026, DeepSeek’s API documentation site published a V4 Preview announcement: two new chat models for the API, a one-million-token context position as the default on official services, open weights and a technical report on Hugging Face, and explicit migration guidance for developers still calling older model IDs- including a sunset timestamp for legacy names.
base_url but switch model to deepseek-v4-pro or deepseek-v4-flash, with Thinking and Non-Thinking modes and OpenAI Chat Completions plus Anthropic-compatible surfaces called out in the same post. Treat benchmark superlatives in marketing copy as claims to verify, not independent lab results.What the official post says shipped
DeepSeek’s news entry positions V4 Preview as live and open-sourced, with consumer access via chat.deepseek.com in Expert Mode and Instant Mode, and the API updated the same day according to that page.
For on-site background on the category, what generative AI is and generative AI use cases by industry still anchor the vocabulary; this page is only about DeepSeek’s April 2026 V4 preview communication on its developer documentation domain.
V4-Pro vs V4-Flash (how DeepSeek frames them)
V4-Pro is described as the heavier line: the post quotes 1.6T total parameters with 49B active, and bundles marketing claims around agentic coding, world knowledge, and math / STEM / coding reasoning versus other open and closed models. Read that language as vendor positioning until you cross-check the exact harnesses and dates on whatever leaderboard or report you trust.
V4-Flash is the smaller line at 284B total / 13B active in the same announcement, emphasising closer reasoning to Pro, parity on simple agent tasks, smaller footprint, faster responses, and economical API pricing — the official per-token table below is copied from DeepSeek’s Models & Pricing page; still re-check that URL before you freeze a budget.

Context length and architecture story
The headline promise in the post is cost-effective one-million-token context, with 1M context as the default across official DeepSeek services in the same wording.
Architecturally, the announcement highlights token-wise compression plus DSA (DeepSeek Sparse Attention), and argues for strong long-context efficiency versus prior generations — useful context if you are budgeting KV memory for agents, but still not a substitute for measuring your prompt templates on your workloads.
Agent tooling mentions
DeepSeek explicitly names Claude Code, OpenClaw, and OpenCode as agent surfaces where V4 is said to integrate cleanly, and states V4 already powers internal agentic coding workflows at DeepSeek. If you are comparing assistants more broadly, Claude vs ChatGPT in 2026 remains the on-site framing piece- orthogonal to whether a given API model ID fits your agent host.
API migration and retirement clock
For HTTP callers, the post’s instruction is blunt: keep your existing base_url and rename the model to deepseek-v4-pro or deepseek-v4-flash. Both models are advertised with 1M context and dual modes (Thinking / Non-Thinking), with a dedicated guide linked from the same news page for thinking behaviour.
The same announcement carries a hard operational note: identifiers deepseek-chat and deepseek-reasoner will become fully retired and inaccessible after 24 July 2026, 15:59 UTC, with interim routing to deepseek-v4-flash in non-thinking and thinking variants respectively. If you still have those strings in config files, treat July as a real outage risk, not a soft deprecation.
The Models & Pricing page adds compatibility detail: deepseek-chat and deepseek-reasoner are marked for future deprecation and currently correspond to deepseek-v4-flash non-thinking and thinking modes respectively.
Official API pricing (per 1M tokens)
DeepSeek bills in USD per one million tokens for input (split into cache hit and cache miss) and output. The same page describes billing as token count × listed price, with charges drawn from your topped-up or granted balance (granted balance used first when both exist). The vendor states that prices may change and asks customers to re-read the pricing page regularly — treat the table below as a snapshot for orientation, not a contract.
| Price component | deepseek-v4-flash |
deepseek-v4-pro |
|---|---|---|
| 1M input tokens (cache hit) | $0.028 | $0.145 |
| 1M input tokens (cache miss) | $0.14 | $1.74 |
| 1M output tokens | $0.28 | $3.48 |
On the same documentation page, both models list a 1M-token context length, a maximum output of 384K tokens, and shared base URLs: https://api.deepseek.com for OpenAI-style Chat Completions and https://api.deepseek.com/anthropic for Anthropic-format calls. Tool calls and JSON output are marked supported for both; FIM completion (beta) is limited to non-thinking mode on both.
For deepseek-v4-flash, the docs state thinking mode supports both non-thinking and thinking, with thinking as the default- see DeepSeek’s Thinking mode guide for how to switch.
What to verify before you promise numbers
- Pricing and quotas- start from the Models & Pricing table (and the snapshot above); do not forward-port yuan-to-dollar stories from trade press without reconciling tiers and cache-hit rules on the official site.
- Benchmark headlines- the API news post repeats strong comparative language; third-party articles such as English summaries on 36Kr Europe add colour and regional angles but are not a substitute for primary tables when you write procurement memos.
- Multimodal gaps- if your workflow needs vision, confirm modality support on the product surface you use; do not infer from text-only API docs alone.
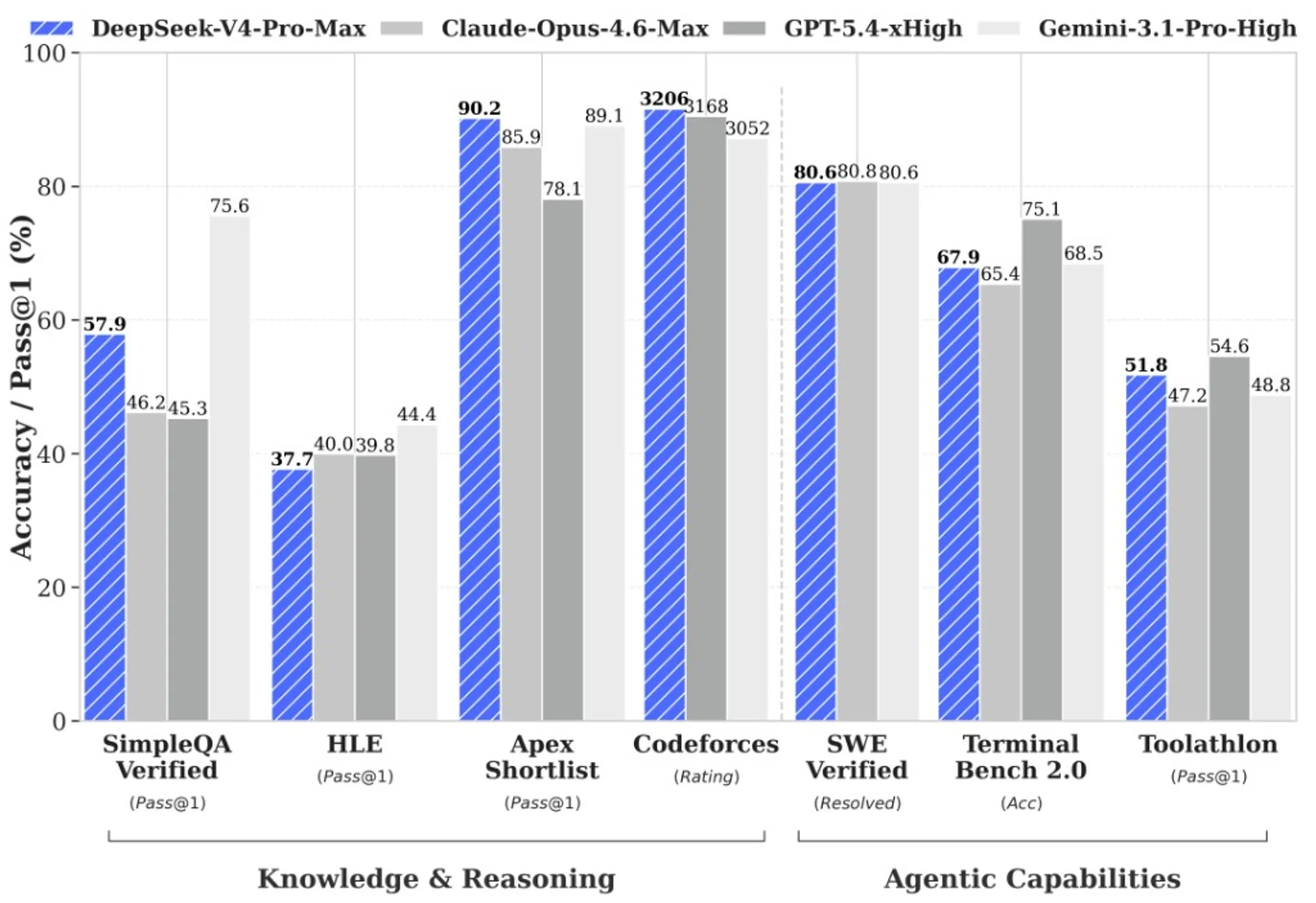
DeepSeek closes the post with a reminder to trust official channels for announcements — sensible hygiene whenever a model drop goes viral.
Sources
- DeepSeek API Docs — Models & Pricing
- DeepSeek API Docs — DeepSeek V4 Preview Release (2026-04-24)
- DeepSeek API Docs — Thinking mode guide
- Hugging Face — DeepSeek-V4 collection (open weights)
- Hugging Face — DeepSeek V4 technical report (PDF)
- 36Kr Europe — commentary on DeepSeek V4 launch and market reaction (secondary press)

The Complete Prompt Engineering for AI Bootcamp (2026)
Available at Udemy — practical coding skills for working professionally with AI (including vendor-named modules such as GPT-5, Veo 3, and Midjourney in the listing). Title, modules, and price change; confirm on the merchant page before you buy.
View course on UdemyFrequently asked questions
Which model string should I use on the API?
Per DeepSeek’s announcement, switch to deepseek-v4-pro or deepseek-v4-flash while keeping your existing base_url. Confirm spelling in your SDK and in the live model list before you deploy.
What happens to deepseek-chat and deepseek-reasoner?
The official post states they route through deepseek-v4-flash today, but will be fully retired after 24 July 2026, 15:59 UTC. Plan config migrations before that window.
Does “1M context default” mean every call is free at 1M tokens?
No. “Default” describes supported window behaviour on official services; your bill still follows the pricing table and any cache rules DeepSeek publishes. Measure with metered test traffic.
Where do Hugging Face links fit?
The announcement points readers to a Hugging Face collection for open weights and a PDF technical report on the V4-Pro model card. Use those for weights and paper detail; use the API docs for HTTP behaviour.
Ship a one-page model ID inventory across staging and prod; the July 2026 cutover is the kind of silent failure that only shows up in logs.